Med det økende antallet informasjonsressurser tilgjengelig er spørsmålet om hvordan lokalisere, hente ut og prosessere informasjon essensielt. Det vil være upraktisk å konstruere ett enkelt samlet system som kombinerer alle disse informasjonsressursene. En mere lovende tilnærming er å bygge spesialiserte case-baserte agenter som samarbeider om å komme frem til en løsning på en gitt forespørsel etter informasjon. Ved å betrakte samlingen av de ulike informasjonsressursene som distribuerte casebibliotek, og ved å benytte eksisterende teknikker for Distribuert Case-Based Reasoning (DCBR) for ressursoppdagelse og utnyttelse av tidligere erfaring, kan Multiagentsystemer (MAS) vise seg å være en meget god løsning.
Jeg vil i denne oppgaven forsøke å presentere anvendelse av agenter og agentarkitekturer innenfor Case-Based Reasoning (CBR). Første kapittel av oppgaven vil være en nokså generell presentasjon av CBR. Deretter vil jeg gå nærmere inn på agenter og disses anvendelse innenfor CBR-domener og applikasjoner. Hovedvekten vil ligge på Distribuerte CBR-systemer og Multiagentsystemer. Begreper som samarbeid, kommunikasjon, kunnskaps- og erfaringsgjenbruk og delt hukommelse (minne) i forbindelse med kompetente agenter vil stå sentralt.
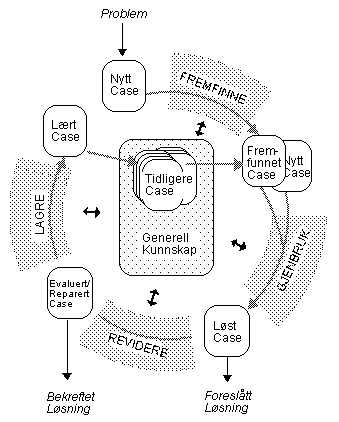
2. Case-Based ReasoningCase-Based Reasoning (CBR) er en generell metode for resonnering på bakgrunn av erfaring. CBR er en lagringsmodell for representasjon, indeksering og organisering av tidligere case, og en prosessmodell for fremfinning og modifisering av gamle case samt assimilering av nye.
Et case beskriver som regel en problemsituasjon. En tidligere erfart situasjon, som har blitt innhentet og lært på en måte som gjør at den kan bli gjenbrukt ved løsing av fremtidige problem, refereres til som et fortidig case. Et nytt case er beskrivelsen av et nytt problem som skal løses. Case-Based reasoning er dermed en syklisk og integrert prosess som består av å løse et problem, å lære fra denne erfaringen, løse et nytt problem, osv.
2.1 CBR-syklusen
Generelt kan en CBR-syklus beskrives gjennom de følgende fire stegene:
1. FREMFINNING av de(t) case(ne) med størst likhet til nytt case.
2. TILPASNING av informasjonen og kunnskapen i caset for å løse problemet (GJENBRUK).
3. REVIDERING av den foreslåtte løsningen.
4. LAGRING av de deler av erfaringen som kan være nyttige for fremtidig problemløsning.
Figur 2.1.1: CBR-syklusen [1].
Fremfinning av case betyr å starte med et (delvist) nytt case, og å finne frem det best matchende tidligere case. Det involverer de følgende suboppgaver:
Identifisere egenskaper - dette kan simpelthen være å identifisere vesentlige trekk ved et case, eller det kan være en mer kompleks evaluering som forsøker å "forstå" problemet i en kontekst. Denne sjekkingen kan gjøres opp mot en kunnskapsmodell (case eller generell kunnskap), eller ved å spørre brukeren.
"Innledende" match (Initially match) - vanligvis gjort i to deler, først en innledende matching prosess som gir en liste med mulige kandidater, som deretter undersøkes nærmere for å kunne velge den beste.
Valg - velg en "best match" fra casene returnert av den innledende matchingen. Resonnereren forsøker å forklare bort ikke-identiske egenskaper. Hvis "matchen" ikke er god nok, søker man etter en bedre ved å f. eks. bruke lenker til nært relaterte case. Utvalgsprosessen kan generere konsekvenser og forventninger fra hvert fremhentede case, ved å bruke en intern modell, eller ved å spørre brukeren.
Tilpasnings- /gjenbruks- steget forsøker å finne forskjellen mellom det nye og det gamle case-et, og hvilken del av det gamle case-et som kan gjenbrukes i det nye. Enten kopieres det gamle case-et, eller det tilpasses.
Kopiere - Forskjellene mellom det nye og det gamle case-et abstraheres, og løsningen kopieres simpelthen fra det gamle case-et til det nye.
Tilpasse - enten kan løsningen selv (transformeres og) gjenbrukes, eller den fortidige metoden som produserte løsningen kan brukes.
Revidering: Hvis løsningen som ble generert fra den forrige fasen ikke er korrekt, så kan systemet lære fra dets feil. Dette involverer:
Evaluering - forsøke løsningen foreslått av tilpasningsfasen i det reelle miljøet den skal operere i og evaluere den.
Reparere feil - Hvis evalueringen av løsningen ga dårlig resultat, finn feilene eller tabbene og generer forklaringer for dem.
Lagring: Inkorporer hva som er nyttig lærdom fra problemløsningsprosessen i den eksisterende kunnskapen. Subprosesser er:
Utvid - hvis problemet ble løst ved hjelp av et gammelt case, kan systemet lage et nytt case, eller generalisere det gamle case-et til å inkludere det nye case-et i tillegg. Hvis brukeren ble forespurt burde et nytt case konstrueres. Forklaringer kan inkluderes i case-et.
Indeksér - avgjør hvilke indekser som skal brukes for fremtidig fremfinning.
Integrer - modifiser indekseringen av eksisterende case etter erfaringen, styrk vektingen av de relevante egenskapene, og svekk vektingen av de egenskaper som førte til fremfinning av irrelevante case.
2.2 Distribuerte Casebaser
En casebase er en kilde av komplekse data lagret i spesielle format. Enhver ustrukturert database, som f. eks. en tekstdatabase, kan konverteres til en casebase ved å generere semantiske metabeskrivelser (descriptors) som karakteriserer hvert dokument i databasen. Mye av arbeidet i informasjonsuthenting og tekstsummering dreier seg om generering av slike "descriptors". Gitt muligheter for "descriptor" generering kan ethvert sett av databaser med inter-relaterte data behandles som distribuerte casebaser. Mange eksisterende applikasjoners informasjonskrav fører til distribuerte casebaser.
Et eksempel hentet fra artikkelen Retrieval and Reasoning in Distributed Case Bases (Prasad et al. [2]) beskriver en automatisert assistent for en risikokapitalist som sender en forespørsel til et multiagent-system. Assistenten setter sammen en agentgruppe ved å la hver agent aksessere sin egen resymédatabase for ulike eksperter for et spesielt aspekt av virksomheten; teknisk, ledelse, salg, etc.. Når gruppen settes sammen må agentene vurdere interaksjoner mellom kravene til ulike eksperter som f. eks., alle eksperter som er villige til å flytte til en bestemt del av landet, eller alle tekniske eksperter i gruppen som kjenner et bestemt datamaskinmiljø. De distribuerte casebasene i dette ekseplet er resymédatabasene for ulik ekspertise, med "descriptor" generatorer som henter ut egenskaper som; "villige_til_flytting_til_sted" og "kjente_datamaskin_miljøer".
Noe forskning har foregått innen distribuerte casebaser i enkeltagentsystemer (Redmond [10] og Barletta et al [11]). Disse deler hvert case inn i sub-case og indekserer disse ved hjelp av både globale mål og den lokale kontekst til det angjeldende sub-case. Denne formen for detaljert utvikling ved å indeksere case-deler basert på både lokale og globale problemløsningskontekster er neppe gjennomførbart for multiagent CBR systemer. Agentene kan bare ha en delvis oversikt over den globale problemløsningskonteksten og den interne konteksten til en case-del. Casebaser for individuelle agenter kan bygges uavhengig, uten kunnskapen om de problemløsende systemer de skal være en del av. På grunn av systemenes enkeltagent natur er behovet for utveksling av informasjon for å løse konflikter ikke en uttalt del av denne forskningen.
Innen multiagentsystemer har det også foregått noe forskning. Artikkelen Corporate Memories as Disributed Case Libraries (Plaza et al. [4]) beskriver alternative måter å oppnå en delt felles hukommelse for agenter i et multiagent-system med distribuerte casebaser. Dette kan oppnås ved hjelp av ulike strategier for samarbeid og kommunikasjon mellom agentene. Teoriene vektlegger samarbeidende fremfinning og sammensetning av case hvor sub-case er distribuert over ulike agenter i et multi-agent system. I slike systemer har hver av agentene en delvis og uperfekt oversikt over problemløsningssituasjonen. Dette skaper et behov for at agentene må kunne samarbeide om å aksessere sine casebaser for å fremhente de beste sub-case. Disse skal videre kunne kombineres på en konsistent måte for å sikre et godt samlet resultat. Hver agents delvise syn kan resultere i beste lokale case, men som når de settes sammen, ikke nødvendigvis resulterer i det beste overordnede case. Dette skaper behovet for samarbeid mellom agentene ved aksessering av casebasene.
3. CBR-agenterPattie Maes, leder av MIT's Media Labs agentgruppe definerer en agent til å være "en prosess som lever i en verden av datamaskiner og nettverk, og som kan operere autonomt for å utføre er sett av arbeidsoppgaver".
Intelligente agenter er datamaskinprosesser som har evnen til å utføre fleksible autonome handlinger i dynamiske, typisk multiagent, domener. Forskning innenfor computer science viser at intelligente agenter kan være nøkkelen til å løse en rekke komplekse software applikasjonsproblemer, som tradisjonelle software engineering verktøy og teknikker ikke har hatt noen løsning for. Multiagentsystemer (MAS) kan blant annet vise seg å være svært anvendbare i forbindelse med Distribuert CBR (DCBR).
Kollektiv intelligens og tilsynekomsten av strukturer gjennom interaksjoner er egenskaper ved MAS. Teori innenfor dette området tar utgangspunkt i "samfunn" av agenter, f. eks. agenter som kan løse samme typer oppgaver, men som har ulike grader av kompetanse for problemområder. Disse egenskapene kan utnyttes i systemer med distribuerte casebaser og åpner for spennende systemarkitekturer. Jeg kommer tilbake til disse egenskapene etterhvert, men først vil jeg nevne litt om hvorfor agenter viser seg å være egnede for og kan optimalisere CBR.
3.1 Selvutviklende Agenter
Tradisjonelt ses case på som passive objekter som venter på å bli hentet frem for videre beslutningstaking eller problemløsning. Et case tilpasser seg ikke til ny tillært informasjon. Avgjørelsen om hvorvidt case skal hentes frem taes av en global mekanisme og individuelle case har liten effekt på fremtidige case valg. Ye Huang foreslår i; An Evolutionary Agent Model of Case-based Classification [7], å la de lagrede casene spille en mer aktiv rolle for å øke fleksibiliteten i fremhentingsprosessen, å la hvert case reflektere over dets egen kontekst og å la case samarbeide med hverandre for å oppnå globale mål. Intelligente agenter kan være løsningen for disse formålene. Agenter er autonome værender som har en viss kontroll over sine egne handlinger. De kan reagere på endringer i omgivelsene og kan kommunisere med andre agenter. Agenter kan i tillegg ha egne mål og evne til å ta initiativ.
I stedet for å behandle casene i casebasen som en passiv masse av tidligere erfaring, vil agentmodellen utvide case til å bli aktive agenter med kunnskap og intensjoner.
3.2 Refleksiv resonnering i en CBR agent
Når en Case-Based Reasoning (CBR) agent utvikler seg over tid, og løser nye problemer basert på tidligere erfaringer, er det noen fallgruver som kan oppstå i dens måte å løse problemer på. Når disse problemene oppstår, er det på tide å starte noen refleksive resonneringsoppgaver for å overkomme disse problemene og forbedre CBR ytelse. Forslaget Sànchez-Marrè et al. foreslår i artikkelen Reflective Reasoning in a CBR agent [8] går ut på å utvide den grunnleggende CBR-syklusen med noen nye refleksive oppgaver, som det å glemme case, lære nye case, oppdatere organiseringen av casebasen, utforske casebasen på nytt, sette meta-case, etc.
Søketiden (effektivitet i tid) ved fremfinning i en casebase kan øke pga. en dårlig organisering av casebasen. For eksempel hvis casebasen er organisert på en hierarkisk måte, f.eks et tre eller nettverk, så kan det oppstå noen stier som direkte ender med en bladnode. I slike stier er det ingen grener i det hele tatt. Hvis den hierarkiske strukturen kan arrangeres på en slik måte at dybden i strukturen blir mindre enn den man allerede har (kompakthet), så kan den gjennomsnittlige fremfinningstiden av case reduseres.
Størrelsen på casebasen (effektivitet i rom) kan øke etterhvert som CBR agenten lærer nye case uten at systemets ytelse forbedres bemerkelsesverdig. En naturlig menneskelig kognitiv egenskap kan være løsningen på dette problemet: Glemsel. Mennesker glemmer kunnskap de ikke bruker. Forhåpentligvis er kunnskap de ikke bruker noe de ikke trenger for å oppnå sine mål. Ved hjelp av denne analogien kan vi hevde at det kan være noen case lagret i casebasen som kan fjernes fra den, med en signifikant økning av ytelse. Forslaget går altså ut på å kategorisere casene: nyttige/unyttige case, normale/eksepsjonelle case, relevante/redundante case, etc., og et nyttighetsmål. I relasjon til denne organiseringen vil man oppnå et relevansmål. Dette målet vil være til hjelp i den refleksive oppgaven det er å lære et nytt case.
Et annet mulig tiltak er å dele case biblioteket i flere case bibliotek med ulik hierarkisk struktur. I fremfinningsfasen vil CBR agenten først søke innen en tidligere etablert klassifikasjon for å identifisere hvilken type case den holder på med. For hver etablerte klasse (meta-case) vil det være et bestemt sett med diskriminerende attributter og et eget case bibliotek. Dermed vil det oppstå en deling mellom case basert på deres likhet til tidligere etablerte meta-case.
Implementasjonen av disse teknikkene i CBR agenten vil føre case biblioteket mot en optimal konfigurering av case, maksimering av kompetanse og minimering av størrelse og responstid (ytelse) til systemet.
3.3 Samarbeidende CBR agenter
Eksplosjonen av elektronisk tilgjengelig informasjon i nettverk har påvirket forskning i retning av å undersøke emner rundt utvikling av automatiserte metoder for samling av informasjon som svar til en forespørsel fra en bruker. Mesteparten av denne forskningen tar utgangspunkt i lokalisering, innsamling og valg av den beste responsen til en forespørsel fra et utall av ulike kilder eller digitale biblioteker. Et alternativ til disse er systemer hvor agenter samarbeider om fremfinning og komposisjon av et case. Ingen enkeltkilde inneholder nødvendigvis den komplette løsningen på en forespørsel. Det kan dermed være nødvendig å sette sammen gjensidig avhengige delvise løsninger fra vesensforskjellige og muligens heterogene kilder. Et eksempel på dette kan være forespørsler i form av spesifikasjoner av designkrav hvor kompatible komponenter utgjør den overordnede utformingen. Agenter samarbeider om fremfinning og komposisjon i systemer hvor sub-case er distribuert over forskjellige agenter i et multiagent-system. Passive datakilder som databaser kan transformeres til pro-aktive agenter ved å pakke dem inn med intelligente grensesnitt. Agentbaserte arkitekturer tilbyr samtidighet, modularitet, robusthet, ansvarsfordeling, og andre fordeler ved distribuerte systemer.
Agentene forhandler for å sette sammen gjensidige akseptable svar på forespørsler. Dette fordi et godt case kanskje ikke er summen av de beste sub-case. Hver agents lokale "syn" kan resultere i beste lokale case, men det er derimot ikke sikkert at det resulterer i de beste case når de sammenlignes på globalt nivå. Dette skaper et behov for at agentene må kunne samarbeide om å aksessere casebasene for å finne frem og samle et godt sammensatt case. Jeg vil i det følgende presentere to teorier for samarbeid mellom agenter.
Forhandlingsbasert Fremfinning
Forhandlingsbasert Fremfinning (Negotiated Retrieval) er en tilnærmingsmåte til problematikken (Prasad et al [2]). Denne strategien består i fremfinning og sammensetting av sub-case fra forskjellige ressurser i et felles minne for å skape et godt samlet case. En forhandlingsdrevet case-fremfinningsalgoritme løser dynamisk inkonsistenser mellom ulike case-deler ved fremfinningsprosessen. Agentene må utvide sine lokale synspunkter med informasjon om begrensninger (constraints) fra andre agenter for å oppnå fremfinning og sammensetning av et bedre overordnet case. Denne strategien involverer at agentene asynkront eksekverer en av de følgende operasjoner: Initiere et sub-case, utvide et eksisterende delvist case, "smelte sammen" eksisterende delvise case eller informere andre om et nytt delvist case.
Initiering av sub-case foregår slik at agenten finner et lokalt sub-case fra dens lokale casebase ved hjelp av en relevant porsjon av brukerspesifikasjonen, som videre kan utvides av andre agenters lokale case. Utviding skjer ved at en agent skaffer seg relevante egenskaper fra en annen agents lokale case som brukes som utgangspunkt for egen case fremfinning. Resultatet integreres med det korresponderende delvise case. Sammensmeltning er lik utvidingsoperasjonen. Resultatet smeltes sammen med det korresponderende delvise case. Informeringen består i at en agent forteller andre om et nytt delvist case som et resultat av en av de tre foregående operatorene. Utviding og sammensmeltning involverer sjekking av eventuelle brudd på lokale begrensninger for settet av egenskaper til det ikkelokale- og det lokale sub- eller delvise case. Oppdagelsen av slike brudd fører til en interaksjon mellom agentene ved at de kommuniserer feedback om årsaker og mulige løsninger. Mottakeragentene assimilerer denne feedbacken og får en forbedret oversikt over de globale kravspesifikasjonene. Noe som gjør at neste initiering, utviding eller sammensmeltning kan unngå de samme konfliktene. En distribuert optimalisering av begrensninger (constraints) er likevel problematisk. Begrensninger har ulike grader av fleksibilitet. Noen er så harde at de må tilfredsstilles i enhver situasjon, mens andre kan være så myke at de kan overses som og når nødvendige.
An agent is competent when it is able to reason about its own competence and that of the other agents with which it cooperates in a given domain. [3, s1]
En kompetent agent er en agent som: 1) er refleksivt bevisst over sin egen kompetanse, for en rekke oppgaver, for å løse problemer, og 2) er bevisst kompetansen til andre samarbeidende agenter i et multiagent-system (MAS).
Dette er utgangspunktet for Federated Peer Learning (Plaza et al [3]), og er en tilnærmingsmåte som lar en agent utnytte erfaringen og ekspertisen til andre agenter for å gjennomføre en lokal oppgave. Samarbeidende problemløsning i et slikt system kan føre til at bred erfaring kan iverksettes på en oppgave. Den baseres på to samarbeidsmodi kalt Distributed Case-Based Reasoning (DistCBR) og Collective Case-Based Reasoning (ColCBR). I DistCBR delegerer en agent A
i ansvaret til en annen "peer" agent Aj for å løse et problem, f. eks. når Ai ikke klarer å løse det på en adekvat måte. I ColCBR beholder derimot agenten ansvaret selv. En agent Ai kan overføre en mobil metode til en annen agent Aj for eksekvering. Ai bruker med andre ord erfaringen akkumulert av andre "peer" agenter mens den selv beholder kontrollen over hvordan problemet skal løses. Hver samarbeidende agent i DistCBR og ColCBR har egenskapene til å løse det overordnede case-et av seg selv (mesteparten av tiden), i motsetning til Forhandlingsbasert Fremfinning hvor agenter er spesialister på spesifikke suboppgaver. Selv om agentene er forsynt med den samme domenekunnskap i utgangspunktet vil de i det lange løp ha hatt forskjellige erfaringer gjennom deres adskilte minne og separate eksistens. Siden hver agent vil ha vært involvert i ulike problemer, oppstår et mangfold som gir grunnlaget for deling og gjenbruk av andre agenters erfaringskunnskap.
Sammenligning av Forhandlingsbasert Fremfinning og FPL
Forhandlingsbasert Fremfinning er basert på en modell hvor svaret til en forespørsel er sammensatt av delvise svar fra distribuerte casebaser. Oppgaver som å sette sammen funksjonelle team, et sett av dokumenter for ulike sider av et prosjekt eller å sette sammen et sett relevante komponenter fra ulike komponentkataloger er eksempler hvor Forhandlingsbasert Fremfinning er et brukbart verktøy for brukerne. På den annen side representerer DistCBR og ColCBR forsøk på å dra nytte av kollektiv erfaring fra ressurser ("peers") i en virksomhet (corporation). Hver av "peer"-agentene kan løse oppgaver på egen hånd, men deres erfaring er forskjellig. Dermed kan hver av dem potensielt bringe unik erfaring til oppgaven, og forskjellene og rikheten utnyttes. Oppgaver som at en prosjektleders agent utnytter erfaringen til sine ressurser ("peers") for prosjektkostnad estimering eller en agent som utnytter erfaringen til en gruppe av ekspertagenter for et nytt marketing initiativ er eksempler hvor disse samhandlingsmodiene kan være nyttige.
DistCBR og ColCBR baserer seg på kunnskapsmodellering og har dermed en kunnskapsintensiv tilnærming til samarbeidende CBR. Forhandlingsbasert Fremfinning har derimot en søke-intensiv tilnærming. Preferanser og ødeleggende interaksjoner håndteres ved å øke fremhentingen av individuelle sub-case ved søking under integreringen.
3.4 Kunnskaps- og Erfaringsgjenbruk (Agenters særkompetanse)
Fokus er fortsatt på samfunn av "peer" agenter og Federated Peer Learning, men jeg vil i dette kapitlet drøfte teorien bak agentenes ulike grader av kompetanse for spesifikke problemområder grundigere. Problemstillingen er at det ofte vil være nødvendig for agentene å dynamisk velge hvilken agent de skal samarbeide med for hver suboppgave innenfor et spesielt problem. Dette problemet gjør at vi må forutsette: 1) at hver agent har en kompetansemodell av de andre agentene, og 2) at hver agent dynamisk kan avgjøre hvilken agent den skal samarbeide med gitt et problem.
Modellen som presenteres er hentet fra artikkelen Knowledge and Experience Reuse through Communication among Competent (Peer) Agents (Plaza et al [3]), og baserer seg på at en agent har kompetansemodeller av seg selv og kompetansemodeller av bekjente agenter i MAS-et. En kompetansemodell til en bekjent agent må eksistere for hvilken som helst oppgave (ved hvilken samarbeid effektueres) og gir kun mening innenfor en gitt samarbeidsmodus.
Kompetent Agent: En kompetent agent er et tuppel A
i(M, B, K, S) med M= M1,…,Mn samarbeidsmodi, B= B1,…,Bm bekjente agenter, Kompetansemodeller K= K1,…,Kk, og refleksive kompetanse modeller (eller kompetansemodeller av seg selv) S.Kompetansemodell: En kompetansemodell K
Є K tilhørende agent Ai er et tuppel K=(B,O,P,M) hvor B Є B, O er en oppgave tilhørende B, P er en problemspesifikasjon og M Є M er en samarbeidsmodus. I tillegg er en kompetansemodell av seg selv S Є S et tuppel av S=(O,P).Kompetansemodellen avhenger av en forespurt agent B, og også av oppgaven O til den forespurte agenten. Kompetansen avhenger videre av typen forespørsel til B angående O: Dette aspektet modelleres på bakgrunn av samarbeidsmodus (DistCBR og ColCBR). I DistCBR deles erfaring i form av case til B med A
i, mens problemløsningskunnskapen brukt for å løse O tilhører B. I ColCBR deles erfaring i form av case til B med Ai, mens problemløsningskunnskapen brukt for å løse O tilhører Ai. Mer om dette senere.Problemspesifikasjon: En problemspesifikasjon P=(PB,E) (til Ai om B for O) består av to modeller; en problembeskrivelse PB og en agent ytelsesevaluering E. En problembeskrivelse PB karakteriserer en rekke problemer som agent B er kompetent for, og vanligvis kan en kompetansevurderende problemløsningsmetode sammenligne det inneværende problem med PB og returnere en vurdering av B sin kompetanse. I tillegg holder modell E informasjon om B sin ytelse vedrørende responsforsinkelse, utilgjengelighetsfrekvens, etc..
Hvis vi forestiller oss at hver kompetent agent i et MAS i utgangspunktet har egenskapene som skal til for å løse alle oppgaver og suboppgaver til et problem, men at graden av validitet vil variere mellom forskjellige problemområder; dette kan virke merkelig i utgangspunktet, men det er det samme som å si at agenter ikke har perfekt kunnskap. Hvilken hensikt skulle det tjene å samarbeide hvis agenten allerede vet alt den trenger? En annen forutsetning er at agentene kan lære fra erfaring. Forutsetningene for MAS i denne sammenhengen er altså at det oppfyller følgende krav:
Homogene Agenter: Representasjonsspråkene til de involverte agentene er det samme. Oversetting er følgelig ikke nødvendig.
"Peer" Agenter: De involverte samarbeidende agentene er ikke spesialister, men skal i utgangspunktet kunne løse den overordnede oppgaven alene. Dette forutsetter en "peer" til "peer" kommunikasjonsform.
Lærende agenter: Agentene tilegner seg den oppgavebaserte kunnskapen som er nødvendig ved å lære fra deres individuelle, vanligvis forskjellige, erfaringer ved problemløsning og ved samarbeid med andre agenter ved problemløsning.
Kommunikasjon og koordinering konstituerer basisen for samarbeid mellom agentene. Samarbeid gjør at en agent kan overvinne oppgaver som strekker seg utenfor dens problemløsningsevner. Samarbeid kan dermed betraktes som en utvidelse av agenters kunnskap. Samarbeidet utføres basert på følgende konvensjoner:
Villighet: Enhver agent i et domene er alltid villig til å samarbeide med andre agenter.
Trofasthet: En agent vil forsøke å fullføre enhver forpliktelse den påtar seg.
Oppriktighet: Agenter vil alltid fortelle hva de tror.
Høflighet: En agent vedkjenner seg alltid forespørsler fra andre agenter.
Når en kompetent agent møter en suboppgave O som er innenfor dens problemløsningsevner så kan den utføre oppgaven på egen hånd. Hvis ikke må agenten samarbeide med andre agenter. Agenten må bestemme:
En kompetent agent A
i(M, B, K, S) kan bestemme når den skal samarbeide takket være sin kompetansemodell av seg selv S, som indikerer dens egen egnethet til å utføre den angjeldende oppgaven. Hvis agenten ikke føler seg kompetent nok, så bør den finne den mest kompetente agenten til å utføre oppgaven utfra andre agenters kompetansemodeller K.En samarbeidsmodus etablerer konvensjonene som et par agenter følger ved utveksling av kunnskap. Samarbeidsmodiene bestemmer handlingene agentene må utføre for å samle de ulike elementene som kreves for å utføre en bestemt oppgave. Samarbeidsmodi etableres avhengig av de følgende aspekter:
For eksempel, agent A som løser en bestemt oppgave O i isolasjon, oppnår de følgende egenskapene:
Tabell 3.4.1 Agent A løser (sub)oppgave O isolert.
|
Agent A |
Agent B |
|
|
Hvor er opphavet til O |
X |
|
|
Hvem eier problemløsningsmetoden |
X |
|
|
Hvem eier datamaskinressursene |
X |
|
|
Hvem eier erfaringen |
X |
På denne måten etablerer en samarbeidsmodus hvordan to agenter må oppføre seg for å løse en bestemt oppgave. Når en kompetent agent imidlertid har valget om mer enn bekjentskap for å samarbeide om å løse en spesifikk (sub)oppgave, så kan ulike samarbeidsstrategier etableres for hver samarbeidsmodus avhengig av forskjellige kriteria fulgt av agenten for å løse en slik (sub)oppgave. For eksempel, avhengig av hvordan settet med hjelpeagenter for samarbeid er konstruert og hvordan dette settet er sortert for traversering i søk etter en kompetent agent. På denne måten kan det sies at en samarbeidsmodus bestemmer hvordan to agenter samarbeider mens en samarbeidsstrategi bestemmer hvordan flere enn to samarbeider.
Uttrykket samarbeidende Case-Based Reasoning samler på denne måten settet av samarbeidsmodiene og samarbeidsstrategiene hvorved hver CBR-agent har sin egen base av tidligere case løst av seg selv. Dermed kan samarbeid mellom CBR-agenter anses som en ekspansjon fra det individuelle minnet til en agent og til det kollektive minnet til CBR-agentene.
Tabell 3.4.2 DistCBR for agentene A og B og agent As (sub)oppgave O.
|
Agent A |
Agent B |
|
|
Hvor er opphavet til O |
X |
|
|
Hvem eier problemløsningsmetoden |
X |
|
|
Hvem eier datamaskinressursene |
X |
|
|
Hvem eier erfaringen |
X |
Tabell 3.4.3 ColCBR for agentene A og B og agent As (sub)oppgave O.
|
Agent A |
Agent B |
|
|
Hvor er opphavet til O |
X |
|
|
Hvem eier problemløsningsmetoden |
X |
|
|
Hvem eier datamaskinressursene |
X |
|
|
Hvem eier erfaringen |
X |
Den grunnleggende forskjellen mellom samarbeidsmodiene består i hvilken agent som eier problemløsningsmetoden som finner det mest relevante case (Tabell 3.4.2 og 3.4.3 forsøker å vise denne forskjellen). I begge modiene er erfaringskunnskap delt og så gjenbrukt av opphavsagenten. DistCBR tillater altså også deling og gjenbruk av hjelperes problemløsningskunnskap, mens i ColCBR så deles problemløsningsmetoden sendt av opphavsagenten med hjelper for å fremfinne de(t) mest relevante case, som senere gjenbrukes av opphavsagenten. Opphavsmannen har altså full kontroll over problemløsningsmetoden.
4. Konklusjon og oppsummeringI denne oppgaven har jeg forsøkt å presentere anvendelser av agenter og agentarkitekturer innenfor Case-Based Reasoning (CBR). Hovedvekten av forskningen på dette området tar for seg Distribuerte CBR-systemer og Multiagentsystemer med fokus på samarbeid mellom agenter som lærer og løser problemer ved hjelp av Case-Based Reasoning (CBR). Ikke alle deler av CBR-syklusen, slik den er beskrevet i kapittel 2 er gjennomgått like nøye i oppgaven. Hovedvekten er lagt på fremfinningssteget og hvordan agenter kan bli bedre til dette gjennom ulike samarbeidsstrategier basert på kompetansemodeller. Jeg har spesielt tatt for meg Forhandlingsbasert fremfinning og Federated Peer Learning.
Forhandlingsbasert fremfinning setter sammen delvise responser fra ulike kilder for å fremskaffe en sammenhengende respons til en forespørsel. Den utvider CBR agenter med distribuert optimering av begrensning (constraint) søkeevner for å unngå ødeleggende interaksjoner mellom case-delene og å samle gode kandidatresponser utfra delvise responser fra individuelle agenter.
Federated Peer Learning (FPL)-basert samarbeidende CBR foreslår to samarbeidsmodi blant CBR agenter for utnyttelse av det "kollektive minne" til "peer"-agenter. I DistCBR overfører en agent oppgaven som skal utføres til en annen agent, og vertsagenten bruker sine CBRmetoder og sin lokale casebase for å føre oppgaven for den andre agenten. I ColCBR overfører en agent oppgaven som skal utføres og metoden som skal benyttes for å utføre den, til en annen agent, og vertsagenten bruker sin lokale casebase sammen med den oversendte metoden for å gjennomføre oppgaven for den andre agenten. Både Forhandlingsbasert fremfinning og FPL-basert samarbeidende CBR passer til ulike typer oppgaver og kompletterer hverandre som verktøy for effektiv kunnskapshåndtering.
5. Referanser[1] Agnar Aamodt og Enric Plaza: Case-based reasoning: Foundational issues, methodological variations, and system approaches. AI Communications, 7(1): 39-59, 1994.
[2] M.V. Nagendra Prasad, Victor R. Lesser, and Susan E. Lander: Retrieval and Reasoning in Distributed Case Bases. Journal of Visual Communication and
Image Representation, Special Issue on Digital Libraries, 7(1):74-87, 1995.
[3] Enric Plaza, Josep Lluís Arcos og Francisco Martín: Knowledge and Experience Reuse through Communication among Competent (Peer) Agents. Dukker opp i International Journal of Software Engineering and Knowledge Engineering i 1999.
[4] M.V. Nagendra Prasad, E. Plaza: Corporate memories as distributed case libraries. Procceding of the 10th Banff knowledge acquisition for knowledge-based system workshop, Banff, Canada, Vol. 2, 1995, pp 40:1-19.
[5] Enric Plaza, Josep Lluís Arcos og Francisco Martín: Cooperative Case-Based Reasoning. I G Weiss (Ed.), Distributed Artificial Intelligence meets Machine Learning, Lecture Notes in Artificial Intelligence, num. 1221: 180-201, Springer-Verlag,1997.
[6] M.V. Nagendra Prasad: Distributed Case-Based Learning. Artikkel skrevet for Andersen Consulting, Center for Strategic Technology Research, Thought Leadership, 1998. (http://www.ac.com/services/cstar/cstr_dcb13.html)
[7] Ye Huang: An Evolutionary Agent Model of Case-Based Classification. I Ian Smith, Boi Faltings (Eds.), EWCBR-96, Advances in Case-Based Reasoning, Springer-Verlag,1996.
[8] M. Sànchez-Marrè, J. Béjar, U. Cortés: Reflective Reasoning in a CBR agent. Procc. of the VIM Project Spring Workshop on Collaboration Between Human and Artificial Societies, Spania, 1997.
[9] Enric Plaza, Josep Lluís Arcos og Francisco Martín: Inference and reflection in the object-centered representation language Noos. Journal of Future Generation Computer Systems, 12:173-188, 1996.
[10] M. Redmond: Distributed cases for case-based reasoning: facilitating use of multiple cases. Proceedings AAAI-90, 1990.
[11] R. Barletta og W. Mark: Breaking cases into pieces. Proceedings of Case-Based Reasoning Workshop, St. Paul, MN., 1998.
[12] M.V. Nagendra Prasad, Victor R. Lesser, and Susan E. Lander: Learning Organizational Roles in a Heterogeneous Multi-agent System. Proceedings of the International Conference on MultiAgent Systems, Japan, November 1996.
[13] Susan E. Lander: Distributed Search and Conflict Management Among Reusable Heterogeneous Agents. Ph.D. oppgave, University of Massachusetts, 1994.
[14] Craig A. Knoblock, Yigal Arens og Chun-Nan Hsu: Cooperating Agents for Information Retrieval. Proceedings of the Second International Conference on Cooperative Information Systems, UoToronto Press, Toronto, 1994.
[15] Jacques Ferber: Multi-Agent Systems, An Introduction to Distributed Artificial Intelligence. Addison-Wesley, 1999.